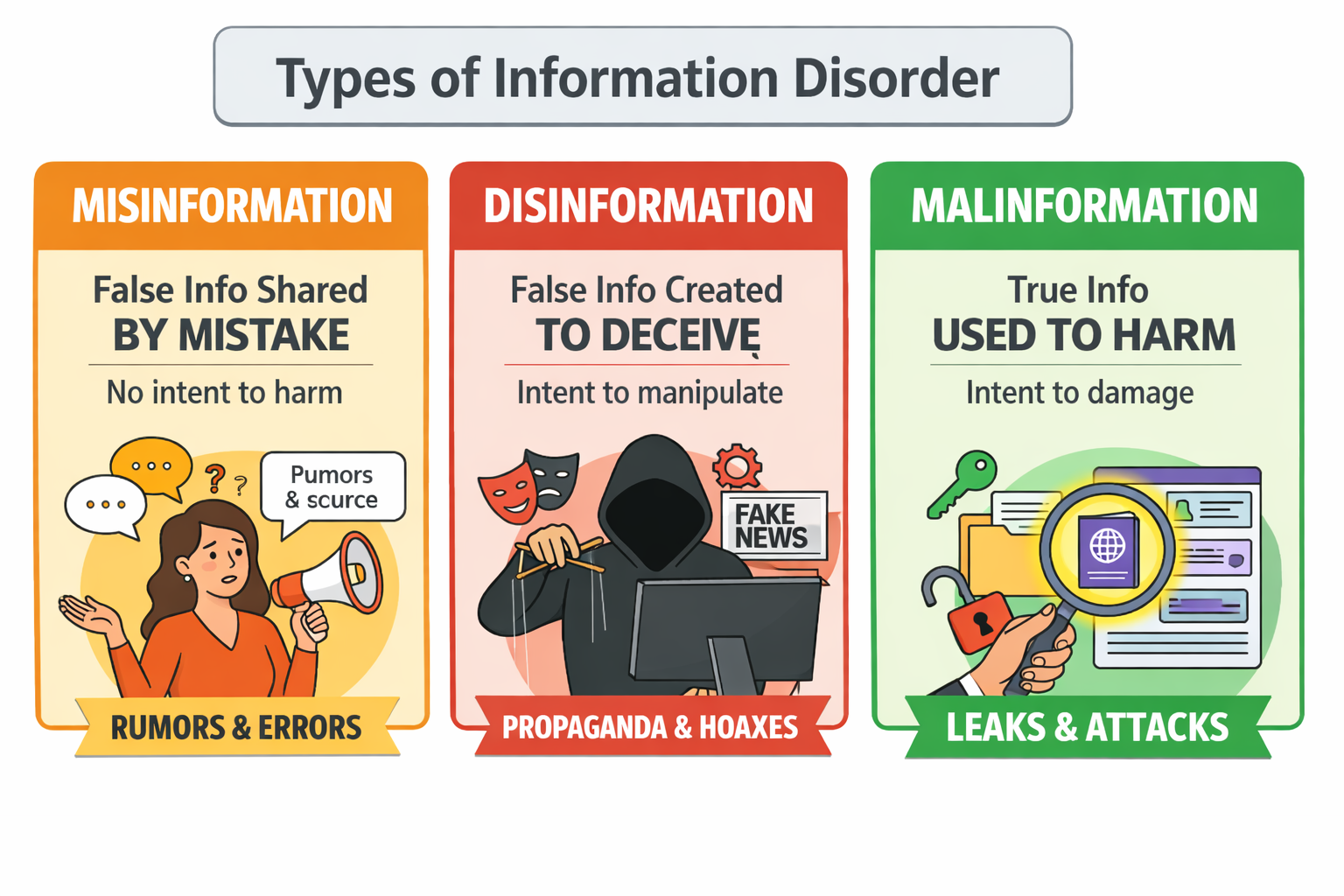
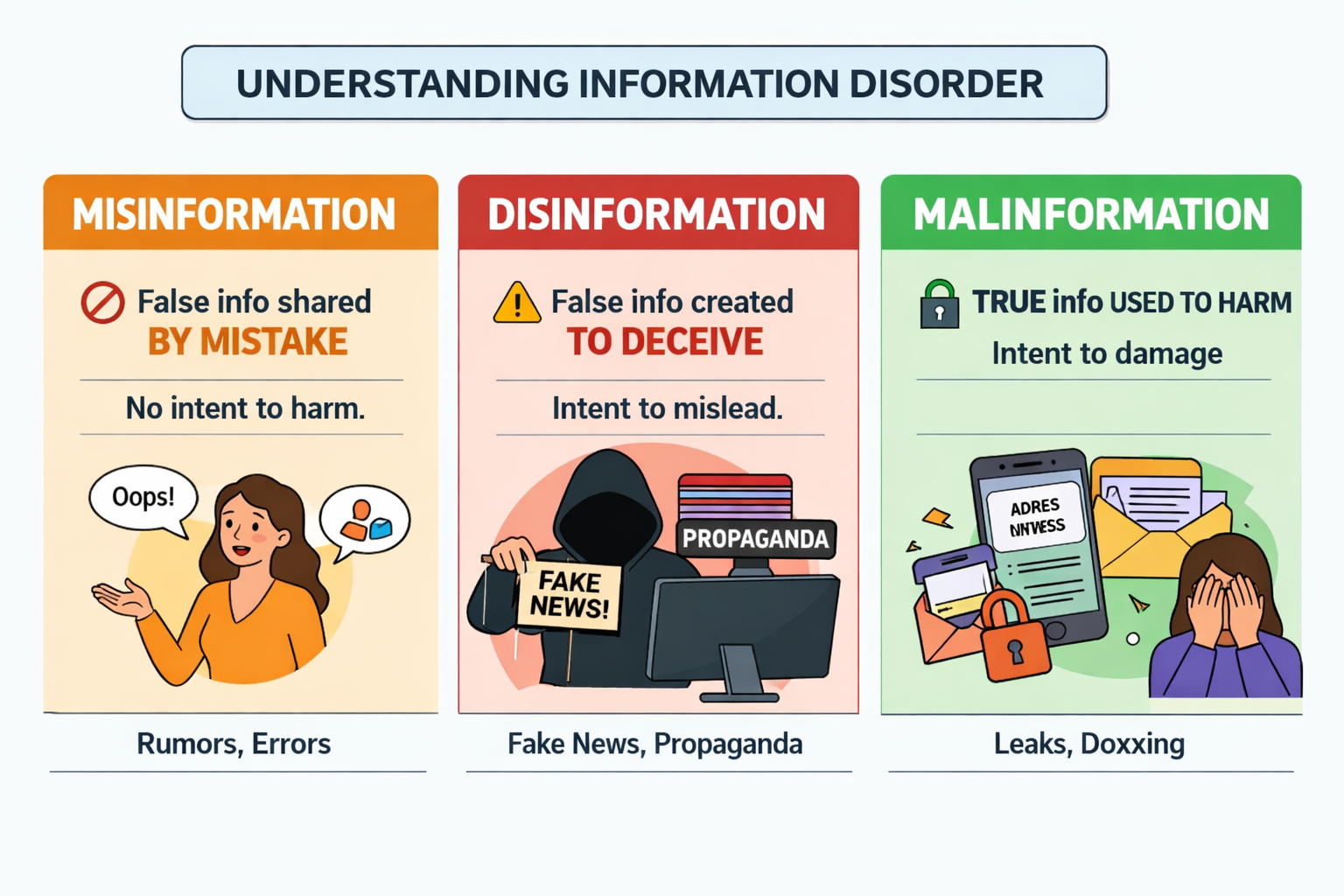
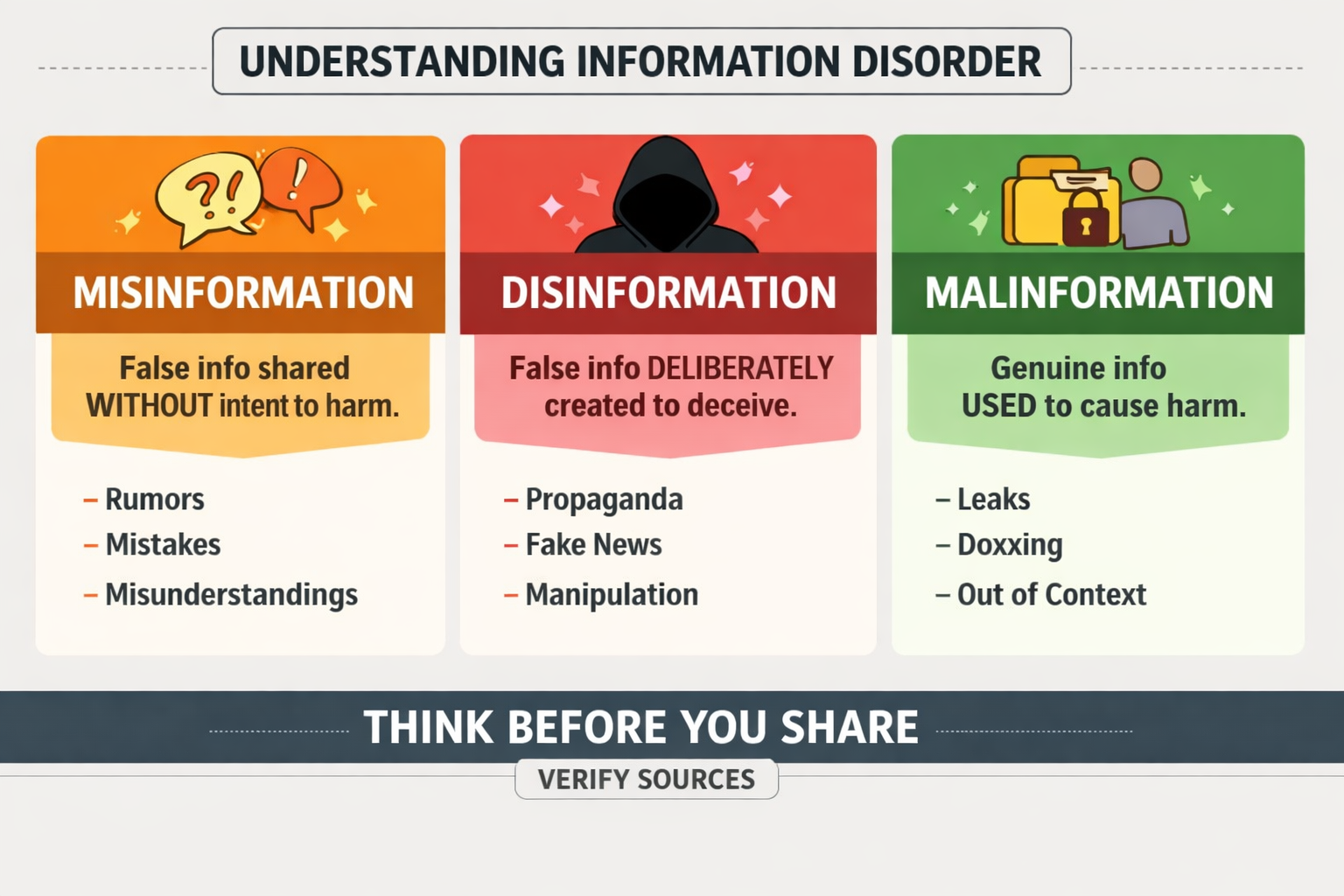
Every day we see posts, videos and messages online. Some are true, some are not. But not all wrong information is the same. Three main types of information disorder help us understand what is happening around us.
Misinformation is false information shared by mistake. People share it because they believe it is true. It often starts from rumours or wrong facts that spread quickly.
Disinformation is false information created on purpose to deceive or manipulate. This is the kind that is made to control opinions or cause confusion. It can appear as fake news or propaganda.
Malinformation is true information used to harm someone. It may be shared out of context or leaked to damage a person’s reputation or safety.
Knowing these differences helps us think before we share. It reminds us to check sources and ask if the message is meant to inform or to influence. In a time when information moves faster than truth, being careful is a form of kindness and responsibility.
Let us build a culture that values truth, empathy and awareness. When we share wisely, we protect not only ourselves but also our community.
Taxonomy is the science of organising and classifying information, and it is an essential skill for librarians who deal with large and diverse collections of books, journals, databases, and other resources. However, creating and maintaining a taxonomy can be a challenging and time-consuming, especially when new topics and terms emerge constantly in the dynamic world of knowledge.
The word “taxonomy” comes from the Greek τάξις (taxis), meaning “arrangement”, “order,” or “sequence”, and -νομία (-nomia), meaning “method”. Taxonomy began as a natural science, with Aristotle proposing a system for classifying living organisms in his work History of Animals. Later, Carl Linnaeus extended this system to include all plants in his work Systema Naturae. Nowadays, taxonomies are used in numerous domains outside biology, such as the library and document classification systems, economics, computing, business models, and personal organisation schemes (Tilton, 2009).
Tok Mun would like to explain how ChatGPT improved my taxonomy creation and development task. First, let us look at how ChatGPT can enhance your life and get you more time for gaming at work (waktu makan tau. Jangan main game waktu kerja, tak berkat).
The benefits of using ChatGPT for taxonomy management
Based on the same concept, we may also apply the process to the creation or development of taxonomy as creating or maintaining terms of taxonomies can be time-consuming and expensive. It is a challenging and time-consuming task, especially for large and complex domains. It requires a lot of domain expertise, research, analysis, and collaboration to create and update taxonomies that meet the needs and expectations of different stakeholders and users.
This is where Chat GPT can help taxonomy managers or precisely you to create and refine taxonomies in a faster and easier way.
Below are benefits of using ChatGPT for taxonomy management:
Chat GPT can generate high-quality and relevant terms and concepts based on the given keywords and characteristics. For example, if you want to create a taxonomy for chatbots, you can provide keywords such as “chatbot”, “conversational AI”, “dialogue system”, etc., and characteristics such as “tone: professional”, “length: short”, “format: list”. Chat GPT will then generate a list of terms and concepts that are related to chatbots and match the characteristics.
Chat GPT can also generate definitions, descriptions, examples, synonyms, antonyms, and other metadata for each term and concept. This can help to provide more context and clarity for the taxonomy users and stakeholders.
Chat GPT can receive user feedback and suggestions to improve the generated text. For example, if you want to change or rewrite some parts of the text, you can provide feedback such as “replace X with Y”, “add Z”, “delete W”, etc. Chat GPT will then modify the text accordingly and generate a new version.
Chat GPT can also learn from previous interactions and preferences to generate more personalized and customized text. For example, if you prefer a certain style or tone of writing, Chat GPT will adapt to your preference and generate text that suits your taste.
Chat GPT can save time and effort for taxonomy managers by automating some of the tedious and repetitive tasks involved in taxonomy creation and maintenance. For example, Chat GPT can generate new terms and concepts based on emerging trends or user queries, update existing terms and concepts based on changes in the domain or user feedback, delete obsolete or redundant terms and concepts based on usage statistics or user feedback, etc.
By using Chat GPT for taxonomy management, you can create and maintain high-quality and up-to-date taxonomies that can enhance your data and content management capabilities. This is a powerful and versatile tool that can help you achieve your taxonomy goals in a more efficient and effective way.
How can ChatGPT be used to generate new terms or categories?
One of the ways that ChatGPT can help you to manage or develop your taxonomy is by generating new terms or categories based on existing ones. For example, if you want to add a new subcategory under the category of “Artificial Intelligence”, you can input the keywords “Artificial Intelligence” and “subcategories” and ChatGPT will generate a list of possible subcategories, such as “Machine Learning”, “Computer Vision”, “Natural Language Processing”, etc. This capability relies on its understanding of the semantic similarity and word associations it has acquired through extensive exposure to vast collections of texts.
By generating new terms or categories based on existing ones, ChatGPT can help you expand your taxonomy and cover more topics and areas of interest. It can also assist you in keeping your taxonomy up-to-date with the latest developments and trends in your field. ChatGPT can help you avoid duplication or inconsistency in your taxonomy by suggesting terms or categories that already exist or are related.
How can ChatGPT be used to generate definitions or descriptions?
ChatGPT can help you to manage or develop your taxonomy by generating definitions or descriptions for terms or categories. For instance, if you want to define the term “Machine Learning,” you can input the keywords “Machine Learning” and “definition,” and ChatGPT will generate a concise and accurate definition, such as “Machine Learning is a branch of Artificial Intelligence that focuses on creating systems that can learn from data and improve their performance without explicit programming.”
This feature is based on ChatGPT’s ability to extract relevant information from various sources and synthesize it into coherent text. By generating definitions or descriptions, it can assist you in clarifying your taxonomy and making it more understandable for your users and colleagues. It can contribute to standardizing your taxonomy, ensuring consistency across different platforms and formats. Additionally, ChatGPT can help enrich your taxonomy, making it more informative and engaging for users and colleagues.
Next we will look into how AI can be used to generate synonyms or related terms.
How can ChatGPT be used to generate synonyms or related terms?
Another way that ChatGPT can assist you in managing or developing your taxonomy is by generating synonyms or related terms for terms or categories. For instance, if you want to find synonyms or related terms for “Natural Language Processing,” you can input the keywords “Natural Language Processing,” “synonyms,” or “related terms,” and ChatGPT will generate a list of options like “Computational Linguistics,” “Text Analysis,” “Text Mining,” and more. This capability is based on the diverse lexical knowledge that ChatGPT acquires from its exposure to various domains and genres of texts.
By generating synonyms or related terms, ChatGPT helps you optimize your taxonomy, making it more flexible and adaptable to different purposes and contexts. It enables you to improve the comprehensiveness and inclusivity of your taxonomy, accommodating different users and perspectives. Additionally, ChatGPT aids in diversifying your taxonomy, making it dynamic and engaging for various users and scenarios.
How can Chat GPT be used to generate examples or applications?
ChatGPT can assist you in managing or developing your taxonomy is by generating examples or applications for terms or categories. For instance, if you want to find examples or applications for the term “Computer Vision,” you can input the keywords “Computer Vision,” “examples,” or “applications,” and ChatGPT will generate a list of possibilities like “Face Recognition,” “Object Detection,” “Self-Driving Cars,” and more. This capability relies on ChatGPT’s creative and generative abilities, allowing it to produce relevant and novel texts based on a given context.
By generating examples or applications, ChatGPT helps you illustrate your taxonomy, making it more tangible and concrete for your users and colleagues. It can also aid in validating your taxonomy, ensuring its relevance and usefulness for your users’ specific needs and goals. Additionally, ChatGPT can inspire curiosity among your users by introducing them to new possibilities within the taxonomy.
Final Thoughts on the benefits and challenges of using ChatGPT for taxonomy management or development?
Using ChatGPT for taxonomy management or development has several benefits and challenges. Some of the benefits are:
Saving time and effort in creating and updating the taxonomy
Enhancing the quality and consistency of the taxonomy
Discovering new trends and insights in the fields of interest
Communicating effectively with users and colleagues in different languages
Some of the challenges are:
Verifying the accuracy and reliability of the generated texts
Adapting the generated texts to the specific needs and preferences of the users
Maintaining the security and privacy of the data and information
Evaluating the ethical and social implications of using NLP tools
Conclusion
ChatGPT is a versatile and valuable tool that librarians can tap to manage or develop their taxonomy in the era of information explosion. By using ChatGPT, librarians can generate new terms or categories, definitions or descriptions, synonyms or related terms, examples applications for their taxonomy based on a few keywords phrases.
However, it is crucial for librarians to be mindful of the challenges and limitations associated with using ChatGPT and to exercise responsible and ethical use. While ChatGPT is capable of generating valuable insights, it is important to remember that it is an AI model and may not always produce accurate or contextually appropriate results. Librarians should employ critical thinking and human judgment when evaluating and validating the generated content.
Ethical considerations are paramount when utilizing ChatGPT. Librarians must ensure that the generated content aligns with legal and ethical guidelines, respects intellectual property rights, and avoids biases or discriminatory language. Additionally, being aware of the biases that may exist within the training data and actively addressing them is crucial to maintain fairness and equity in the outputs.
In summary, while ChatGPT offers valuable support for taxonomy management, librarians must approach its usage with caution. By combining the capabilities of ChatGPT with human expertise, critical evaluation, and ethical considerations, librarians can harness its potential while addressing the challenges and limitations that come with it.
References
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., & Hesse, C. (2020). Language Models are Few-Shot Learners. Arxiv.org. https://arxiv.org/abs/2005.14165
Dathathri, S., Madotto, A., Lan, J., Hung, J., Frank, E., Molino, P., Yosinski, J., & Liu, R. (2020). Plug and Play Language Models: A Simple Approach to Controlled Text Generation. ArXiv:1912.02164 [Cs]. https://arxiv.org/abs/1912.02164
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv.org. https://arxiv.org/abs/1907.11692
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Tilton, L. (2009, January 10). From Aristotle to Linnaeus: the History of Taxonomy – Dave’s Garden. Www.davesgarden.com. https://davesgarden.com/guides/articles/view/2051
Librarians face the challenge of managing and organising an ever-expanding collection of digital assets. With an overwhelming number of files in different formats and sizes, it’s easy to feel overwhelmed and lost in the chaos. Have no fear. Tok Mun will help you to conquer the chaos and take control of your digital assets like a real librarian.
Embracing AI in Digital Asset Management
Digital asset management is the process of storing, categorising, and retrieving digital files. It is a critical part of any librarian’s job, as it helps to ensure that files are easy to find and use.
This is where ChatGPT can help. ChatGPT is a powerful natural language processing (NLP) tool that generates text based on input. You can use ChatGPT to create folder names and descriptions that are relevant, informative, and concise. ChatGPT can also suggest alternative names and descriptions that suit your needs better.
Step 1: Define your main categories
The first step is to define your main categories of files. These are the top-level folders that will contain your subfolders and files. You can use broad terms that capture your files’ general theme or purpose. For example, if you have a collection of books on various topics, you can use the following main categories:
Fiction
Non-fiction
Reference
To create these folders, you can type them in your file explorer or use ChatGPT to generate them for you. To use ChatGPT, you can enter a prompt such as “Generate three main categories for a library collection of books on various topics.” ChatGPT will then produce a list of possible folder names based on your prompt. For example:
Literature
Information
Resources
You can choose the folder names that best suit your needs or modify them as you wish.
Step 2: Create subcategories
The next step is to create subcategories for each main category. These second-level folders will further divide your files into more specific groups. You can use more detailed terms that describe the subtopics or genres of your files. For example, if you have a fiction category, you can use the following subcategories:
Fantasy
Mystery
Romance
Science Fiction
To create these folders, you can type them in your file explorer or use ChatGPT to generate them. To use ChatGPT, you can enter a prompt such as “Generate four subcategories for fiction books.” ChatGPT will then produce a list of possible folder names based on your prompt. For example:
Adventure
Crime
Historical
Horror
You can choose the folder names that best suit your needs or modify them as you wish.
Bonus:
Here are some more examples of how ChatGPT can generate different folder names based on different prompts:
Generate four subcategories for non-fiction books.
Biography
History
Science
Self-help
Generate four subcategories for reference books.
Dictionaries
Encyclopedias
Manuals
Guides
Generate four subcategories for visual arts books.
Painting
Sculpture
Photography
Graphic Design
Step 3: Add descriptions
The final step is to add descriptions for each folder. These are short sentences that explain what each folder contains and why it is important. Descriptions can help you, and others understand the purpose and content of each folder at a glance. They can also help you avoid confusion and duplication of files.
To create these descriptions, you can type them in your file explorer or use ChatGPT to generate them. To use ChatGPT, you can enter a prompt such as “Generate a description for the fantasy subcategory.” ChatGPT will then produce a sentence based on your prompt. For example:
Fantasy is a subcategory of fiction that features imaginative and magical elements such as wizards, dragons, and quests.
You can choose the description that best suits your needs or modify it as you wish.
Step 4: Review and improve
Once you have created your folder structure, you can review it and see if it meets your needs and expectations. You can also use ChatGPT to help you improve your folder structure by providing feedback and suggestions.
To use ChatGPT for this purpose, you can enter a prompt such as “Review my folder structure and suggest how to improve it.” ChatGPT will then analyze your folder structure and produce a list of possible improvements based on your prompt. For example:
Consider adding more sub categories to non-fiction to cover more topics such as biography, history, science, etc.
Consider renaming resources to references to avoid confusion with information.
Consider adding more descriptions to explain the difference between literature and fiction.
Consider using consistent capitalization and punctuation for all folder names and descriptions.
You can choose the improvements that best suit your needs or ignore them as you wish.
Final Thoughts
ChatGPT is a powerful tool to help you create and manage your folder structure effectively. By using ChatGPT, you can save time and effort in creating folder names and descriptions that are relevant, informative, and concise. You can also benefit from ChatGPT’s feedback and suggestions to improve your folder structure and make it more logical, consistent, and intuitive.
We hope this blog post has given you some insights into how to leverage ChatGPT for effective folder structure management.
As a librarian, we are required to keep up with the latest technology to provide the best possible service to our users. I am more than happy to introduce ChatGPT – a revolutionary tool that can help to streamline your workflow and enhance communication with our users or, to be precise, your users. In this post, we will explore some of the benefits of ChatGPT and how you, my librarian friends, can use it, and leverage it to bring your library services to greater heights.
Get ready to be revolutionised.
What is Chat GPT and How Can it Help Librarians?
ChatGPT is a web-based chatbot that can help you with a variety of tasks, including providing reference services, circulation services, and research assistance. In addition, this AI can also help you to keep track of your to-do lists, manage your time more effectively, and stay organised.
Why should you leverage ChatGPT?
There are many advantages of using ChatGPT. For example, ChatGPT can help you to save time by automating tasks that would otherwise need to be done manually. In addition, ChatGPT can also help you to improve your workflow by providing you with an easy way to access information and resources. It can also assist you in reducing your workload by taking on some of the tasks that you would otherwise need to do yourself.
Automate Research with ChatGPT
As librarians or some might call us the Information Professionals, we know that research can be a time-consuming and tedious process. But what if there was a way to automate research with the help of ChatGPT?
ChatGPT is an artificial intelligence chatbot that can help you with your research. All you need to do is type in your question, and ChatGPT will search through billions of documents to find the answer for you. You can also ask follow-up questions to refine your results.
Not only does ChatGPT save you time, but it can also help you expand your research horizons by providing you with new ideas and perspectives that you may not have considered before. So why not give it a try? (I am not affiliated with nor doing any promotional activity for ChatGPT). You may just be surprised at how much ChatGPT can help revolutionize your workflow!
Increase Productivity with ChatGPT
We are under constant pressure to do more with less. We are expected to be knowledgeable about an ever-increasing range of topics, and we must be able to find the information our users need quickly. Adding ChatGPT to your workflow can help streamline the process and make getting the information you need easier.
ChatGPT instantly connects you with a network of research librarians who can help you with your questions. You can also search the ChatGPT Knowledge Base for answers to common questions. And if you need more help, ChatGPT offers live chat support 24/7.
ChatGPT is easy to use and integrates seamlessly with your existing workflow. There’s no software to install, and it works on any device. With a caveat, please do not share, never share any sensitive or propriety information of your organisation with ChatGPT. (Read: Samsung bans ChatGPT use after employee leak | TechRadar). With ChatGPT, you can finally get the information you need without having to search through endless resources.
Examples of Using Chat GPT in Libraries
Chatbot for Reference Services: Libraries can use Chat GPT to create a chatbot that can answer reference questions from patrons. This can be done using a platform like Facebook Messenger, where patrons can send their questions to the library’s page and receive automated responses powered by Chat GPT.
Virtual Writing Assistant: Libraries can integrate Chat GPT into their online writing resources to offer a virtual writing assistant to their patrons. Patrons can input their writing and receive feedback and suggestions for improvement from Chat GPT.
Personalized Reading Recommendations: Libraries can use Chat GPT to offer personalized reading recommendations to their patrons. Patrons can provide information about their reading preferences, and Chat GPT can suggest books and authors that might interest them.
Interactive Storytelling: Libraries can create interactive storytelling experiences using Chat GPT. Patrons can input their own ideas and responses, and Chat GPT can generate a story that incorporates those elements.
Language Learning: Libraries can use Chat GPT to create language learning resources for their patrons. Patrons can input text in the language they are learning, and Chat GPT can provide feedback and suggestions for improvement.
Disclaimer: I use ChatGPT to generate these examples
Benefits of using ChatGPT for Reference Services
One of the best ways to revolutionise your workflow as a librarian is to take advantage of ChatGPT, an online chat service that can be used for reference services. Here are some of the benefits of using ChatGPT for reference services:
You can save time by quickly answering questions from patrons without having to schedule appointments or track down specific reference materials.
You can improve patron satisfaction by giving them more immediate answers to their questions.
You can reach more patrons by being available 24/7, which is especially useful for those who live in different time zones or have scheduling conflicts.
You can provide more personalized service by getting to know your patrons better and understanding their unique needs.
You can increase efficiency by handling multiple chats simultaneously and quickly transferring chats to other librarians if necessary.
Considerations and Drawbacks to Using ChatGPT
As useful as it is, you should be aware of a few key considerations and drawbacks to using ChatGPT before deciding if it’s the right tool for your workflow.
First, ChatGPT is built on top of the GPT-3 platform; it inherits some of the same limitations. For example, GPT-3 has difficulty understanding long or complex questions, so you will need to keep the questions concise when using ChatGPT. Additionally, GPT-3 cannot answer questions about specific library catalogues or databases, so you will need to supplement ChatGPT with other search tools when working with users.
Second, while ChatGPT can answer simple questions quickly, it is not yet advanced enough to handle more complicated reference inquiries. You will need to be prepared to step in and provide assistance when ChatGPT cannot satisfy your or your users’ needs.
And finally, ChatGPT knowledge or databases is limited up to September 2021. In other words, ChatGPT does not have information on events or developments that have occurred after that date.
As with any new technology, there is a learning curve associated when using ChatGPT. Before using it, you will need to take some time to familiarise yourself with the tool and its capabilities.
Final Say: Revolutionise Your Workflow with Innovative Technology
The ChatGPT is a revolutionary new artificial intelligence chatbot that has the potential to revolutionise your workflow. It is designed to help you manage your work more efficiently and effectively by automating tasks that would otherwise take up your valuable time. It can suggest tools and apps that can help you schedule appointments, send reminders, and order supplies. ChatGPT can also provide tips and strategies for time management, organisation, and productivity that can be useful in performing those tasks.
References
Baker, A. (2019, March 13). Revolutionize Your Workflow: A Guide for Librarians on Using ChatGPT.
O’Connor, L. G. (2021). AI Chatbots in Libraries: A Review of Current Practices and Future Directions. Journal of Library Administration, 61(4), 378-393.
Retrieved from https://blog.chatgpt.com/revolutionize-your-workflow-a-guide-for-librarians-on-using-chatgpt/
Rader, H., & Hirshon, A. (2021). Libraries and Artificial Intelligence: Opportunities and Challenges. Journal of Librarianship and Information Science, 53(1), 27-40.
Liu, J., Mao, J., Lu, L., & Jiao, L. (2021). Using Chatbots for Reference Services: A Systematic Literature Review. Journal of Academic Librarianship, 47(2), 102252.
Chen, Y., Huang, H., & Wang, C. (2021). Using Chatbots to Provide Reference Services in Academic Libraries: A Case Study. Journal of Academic Librarianship, 47(3), 102305.
Skirpan, M., & Harlow, S. (2021). Chatbots in Academic Libraries: An Exploratory Survey of Current Practices and Perceptions. College & Research Libraries, 82(2), 238-255.
Artificial intelligence (AI) is a rapidly evolving technology that can potentially transform librarianship in various ways. AI can be defined as “the ability of machines to do things that people would say require intelligence” (Jackson, 1985). AI can enable new capabilities to address users’ information needs, such as providing not just information but deep intelligence and offering “Insight As A Service (IAAS)” (Springer Nature, 2019). While AI can also enhance and augment many library services and workflows, such as content indexing, classification, search and discovery, data analysis and visualization, chatbots, and virtual assistants, AI, however, also poses some challenges and ethical issues for librarians, such as privacy, bias, accountability, transparency, and trust.
As librarians, we need to be aware of the impact of AI on our profession and our users and actively participate in designing and evaluating AI-based tools and applications. We also need to update our skills and knowledge to keep up with the latest trends and developments in AI and related technologies.
We will explore some of the ways in which AI would change the role of libraries in these three main areas:
Content Indexing
Virtual Assistants and
Data Visualisation
We will also look into opportunities that we, as a librarian, can leverage AI to improve library services.
Content Indexing
Content indexing is the process of assigning keywords, subject classification or metadata to documents or any library resources to facilitate content discovery for retrieval and use. This has always been done manually, and it proves to be a tedious task even for experienced librarians. The process typically involves analysing the text of the content to identify keywords, phrases, and other metadata that can be used to describe the content and facilitate retrieval. Naturally, this is a vital process of any library information system, not limited to search engines, content management systems, and digital assets management systems.
Libraries can leverage the speed of AI to automate and improve this process by utilising natural language processing (NLP) and machine learning (ML) capabilities to analyse digital collections and identify relevant topics and thus assign suitable metadata to improve search and discovery. We look at how Springer Nature employs AI to index its vast collection of eBooks and provide semantic search capabilities (Springer Nature, 2019).
We can tap into this capability and benefit from AI-powered content indexing by accessing more comprehensive and accurate metadata in our collections, which at the end of the day, shall improve search results with precision. Similarly, ML may group or cluster documents of similar concepts as a result of enhanced classification schemes, taxonomy and ontologies.
Virtual Assistants (VA)
Virtual assistants or digital assistants are applications that use natural language understanding (NLU) and speech recognition to interact with users via voice or text (Read: 26 Actually Useful Things You Can Do with Siri). VAs may perform various tasks for users, such as answering questions, providing information, setting reminders, playing music or controlling smart devices. Some of the most popular VAs are Google Assistant, Siri, Alexa and Cortana.
VAs have also entered libraries in the form of chatbots that can handle directional questions on a library website, alert when a book is due, point a user to relevant library resources or answer simple informational requests (Hervieux & Wheatley, 2020). In the future, VAs may be able to provide more advanced services for our users, such as recommending books or articles based on user preferences or context, summarizing key points or arguments from a document or dataset, or generating citations or bibliographies. We can use VAs to enhance our user experience and satisfaction and reduce their workload for repetitive or routine tasks. We can also collaborate with VAs developers to ensure that they are reliable, accurate and ethical.
Data Visualisation
Generally, data visualization is the process of presenting data in graphical or pictorial forms to communicate information effectively and efficiently. This can help or aid users to better understand complex data sets, discover patterns or trends, compare variables or categories, or tell stories with data.
Data visualisation tools can use AI to analyze data and generate visualisations automatically or semi-automatically based on user input or preferences. For example, SciGraph Explorer is a data visualization tool that uses AI to map connections among concepts, researchers and institutions based on Springer Nature’s publications (Springer Nature, 2019). We can use data visualization tools to provide IAAS for our users by helping them find unexpected connections or insights from existing data sources. We can also use data visualization tools to showcase our own collections or services in an engaging and interactive way.
Conclusion
AI is changing libraries in many ways by offering new possibilities for improving library services and workflows. We need to embrace AI as an opportunity rather than a threat by learning about its potential benefits and challenges for our profession.
References:
Jackson, P. (1985). In Introduction to artificial intelligence. essay, Dover Publications.
The impact of Artificial Intelligence on librarian services | For Librarians | Springer Nature. (2019, July 21). The Impact of Artificial Intelligence on Librarian Services | for Librarians | Springer Nature. https://www.springernature.com/gp/librarians/news-events/all-news-articles/ebooks/the-impact-of-artificial-intelligence-on-librarian-services/16874432
Wheatley, A., & Hervieux, S. (2020, February 6). Artificial intelligence in academic libraries: An environmental scan. Information Services & Use, 39(4), 347–356. https://doi.org/10.3233/isu-190065
IFLA Trend Report — Advances in Artificial Intelligence. (n.d.). IFLA Trend Report — Advances in Artificial Intelligence. https://trends.ifla.org/literature-review/advances-in-artificial-intelligence
Are you curious about the contrasting roles of librarians and knowledge managers? You’re certainly not the only one! Despite sharing a focus on information management, these professions have unique responsibilities and duties. This article aims to delve into the distinctions between librarians and knowledge managers, providing insights to help you determine which career path may align better with your interests. Prepare to embark on an exciting journey into the world of information professionals!
What is a Librarian?
Librarians are expertly trained professionals who specialise in information and its management. They can work in various settings, such as public, academic, corporate, government, and medical libraries. Typically, librarians hold a master’s degree in library science from an accredited institution.
In contrast, knowledge managers are also trained professionals that work with information and knowledge, but they focus primarily on the needs of organisations rather than individuals. Knowledge managers usually possess a background in business or management and may hold a degree in library science or a relevant field. They work in diverse settings such as businesses, governments, nonprofits, and educational institutions.
What is a Knowledge Manager?
The responsibility of a knowledge manager or a team of knowledge managers is to procure, systematise and preserve information within an organisation. The purpose of this role is to guarantee that accurate and relevant information is accessible to the appropriate individuals at the necessary time.
To achieve this goal, a knowledge manager may have to develop and execute policies and procedures associated with information management, such as document control and records management. They may also need to construct taxonomies, ontologies, and other controlled vocabularies to facilitate information organisation. Additionally, a knowledge manager may provide staff training on using information management systems.
Differences between the Two Roles
Libraries and library science programs have long been a source of training and education for people who want to enter the field of information management. In recent years, “knowledge management” has become more common in business and academic circles, leading some people to believe that the two terms are interchangeable. However, there are important distinctions between the roles of librarians and knowledge managers.
Librarians are primarily concerned with organising, storing, and retrieving information. They use their research and information literacy skills to help patrons find resources. Knowledge managers, on the other hand, are focused on using knowledge to achieve organisational goals. They may develop systems and processes for gathering and sharing knowledge or create training programs to help employees better use information.
Both librarians and knowledge managers play essential roles in organisations, but their approaches to managing information differ. Librarians focus on access to information, while knowledge managers focus on using knowledge to improve decision-making and organisational performance.
Commonalities between the Two Roles
Librarians and knowledge managers share several similarities. Both require extensive knowledge of information and its organisation and exceptional research and analytical skills. Additionally, effective communication with others, often to share their expertise, is crucial in both roles.
Despite their similarities, there are some significant differences between the two professions. Librarians generally grant access to information resources, while knowledge managers focus on producing and distributing new knowledge. Furthermore, librarians usually work within a single organisation, while knowledge managers may partner with multiple organisations or individuals.
Should you have them both in an Organisation?
Well, it depends. However, saying this as a librarian may be considered arbitrary, as this is my role. It will always be based on personal whim, preference and subjective judgement rather than objective or rational criteria.
However, having both roles in an organisation can offer numerous advantages. Below are some of the benefits:
Having both roles in an organisation can help to increase efficiency as the knowledge manager can help direct the librarian to relevant resources, and the librarian can provide expertise on using those resources.
The knowledge manager can help ensure that the organisation’s output is high quality by working with the librarian to develop quality control procedures.
Having both roles in an organisation allows for greater flexibility as the responsibilities of each position can be adjusted as needed to meet the organisation’s changing needs.
The knowledge manager and librarian can work together to enhance organisational communication by developing and implementing effective communication strategies.
The knowledge manager and librarian can work together to improve the organisational culture by promoting a culture of lifelong learning and collaboration.
Now, let us discuss the challenges of having both roles in an organisation.
Challenges of Integrating Both Roles in an Organisation
Libraries and library staff have always been at the forefront of managing and disseminating organisational knowledge. In recent years, however, there has been an increased focus on the role of knowledge management (KM) within organisations. This has led to a debate over the distinctions between librarians and KM professionals and what each role entails.
Several challenges come with integrating both roles within an organisation. Firstly, there is a need to establish clear lines of communication and collaboration between the library and KM teams. Secondly, there needs to be a shared understanding of the goals and objectives of each group to avoid duplication of effort or conflict. It is crucial to ensure that library and KM staff have the necessary skillsets to carry out their respective roles effectively.
With careful planning and execution, however, these challenges can be overcome. By working together, librarians and KM professionals can create a dynamic and effective knowledge management system that meets the needs of all organisational stakeholders.
Integrating librarian and knowledge manager roles in an organisation can present some challenges. Below are a few examples:
Role definition: There may be confusion over the specific responsibilities of each role, leading to overlaps or gaps in duties.
Communication barriers: Different terminology and practices used by librarians and knowledge managers can create communication barriers that must be overcome for successful collaboration.
Resistance to change: Implementing changes to integrate both roles may face opposition from staff accustomed to traditional ways of doing things.
Resource allocation: Providing the necessary resources and funding for both roles can be challenging, especially in smaller organisations.
Training and development: Ensuring both roles have adequate training and development opportunities to keep up with changing technology and trends can also be challenging.
Summary
I trust this article has provided valuable insights into the differences between librarians and knowledge managers. While librarians focus on information organisation, knowledge managers leverage technology to enhance the accessibility and usefulness of data. Both roles play crucial parts in facilitating access to resources necessary for success. With increasing dependence on digital tools for information management, comprehending the distinctions between these related professions becomes critical for organisations.
Hari ini saya hendak bercerita tentang sedikit programming language iaitu PHP. Semasa saya bekerja di Open University Malaysia dahulu kala, saya ada menulis script untuk Drupal untuk dapatkan image dari server LibraryThing dan muat-turun gambar tersebut ke server kita. Adapun tujuan ini adalah untuk mengurangkan tekanan bandwidth kepada pengguna ketika itu. Umumnya pada waktu ini, mungkin tidak relevan lagi kerana rata² masyarakat mempunyai akses kepada internet super.
Namun pada hari ini, API LibraryThing telah dihentikan sehingga diberitahu kelak (tak tahu la sampai bila). Takper, script ini adalah bebas untuk kita tukar source server kepada servis yang lain.
API LibraryThing dihentikan buat sementara waktu
Sebagai penambahbaik servis Perpustakaan Digital OUM ketika itu, saya telah menulis script untuk mendapatkan data² dari Syndetics untuk memperkayakan atau enrich Katalog OUM mereka dengan Muka Buku, Ringkasan Buku dan sebagainya.
Pengkayaan Katalog dengan Servis Syndetics
Script yang saya tulis untuk Perpustakaan Digital Tan Sri Abdullah Sanusi akan menyimpan Book Summary, Publisher, Author dan juga Imej Muka Buku ke dalam sistem secara dinamik.
Buku di Perpustakaan Digital Tan Sri Abdullah Sanusi
Melalui script ini, pengguna hanya perlu memasukkan No ISBN buku tersebut dan yang lain² akan dilakukan secara dinamik oleh server. Mudah bukan? Masukkan ISBN, semua data² akan diambil dan disimpan di dalam database.
Muat-turun Book Cover ke Server
Hari ini, saya ingin berkongsi maklumat atau script tentang cara² mendapatkan gambar dari server lain dan seterusnya menyimpan gambar tersebut ke dalam server kita. Script ini juga akan menyusun dan menyimpan gambar² buku mengikut jumlah askara ISBN samada 10-askara atau 13-askara.
Dalam erti kata lain, script ini akan create folder kepada beberapa bahagian kecil di dalam format 3/3/3/3/1. Sebagai contoh, jika ISBN yang diberikan adalah 978-0735210967, maka script ini akan create folder dan subfolder seperti berikut:
978/073/521/096/7
Ini adalah untuk mengelakkan daripada server mempunyai ribuan folder dengan no ISBN yang banyak yang pasti akan membebankan server apabila pengguna browse folder ini menggunakan SFTP atau FTP.
Langkah yang bijak adalah dengan memecahkannya kepada beberapa cluster. Ini akan membantu untuk mengurangkan pengunaan folder yang banyak apabila koleksi buku anda lebih dari 100,000.00.
Memecahkan ISBN kepada beberapa kluster
Kita ambil contoh ISBN untuk buku² di bawah:
978-1621001539
978-9971693367
978-0415834841
978-1840760378
Di dalam keadaan biasa, selalunya adalah mudah untuk kita terus create folder (4 Folder) untuk setiap ISBN di atas. Jika kita berbuat demikian, sekiranya buku yang kita serve adalah kurang dari 1,000, ini mungkin tidak menjejaskan prestasi server. Namun Perpustakaan jarang sekali ada buku dengan jumlah seperti itu. Selalunya pasti lebih daripada 10,000 judul dan jika kita teruskan juga, tidak ada salahnya, tapi nanti di dalam 1 folder akan ada beribu folder yang pastinya tidak baik untuk kesihatan Server Admin (sian pada dia).
Perasan tak kebanyakan ISBN ada mempunyai prefix yang sama seperti berikut:
9780415778299
9780415820349
9780415809771
9780415442060
9780415579841
Dengan menggunakan kaedah clustering ini, mereka boleh kongsi folder yang sama dibawah “/978/041/”. Ini akan membantu untuk mengurangkan kepada pembentukkan folder di dalam jumlah yang banyak.
Fungsi di bawah ini yang memecahkan folder kepada beberapa cluster, Lihat $parts = Array.
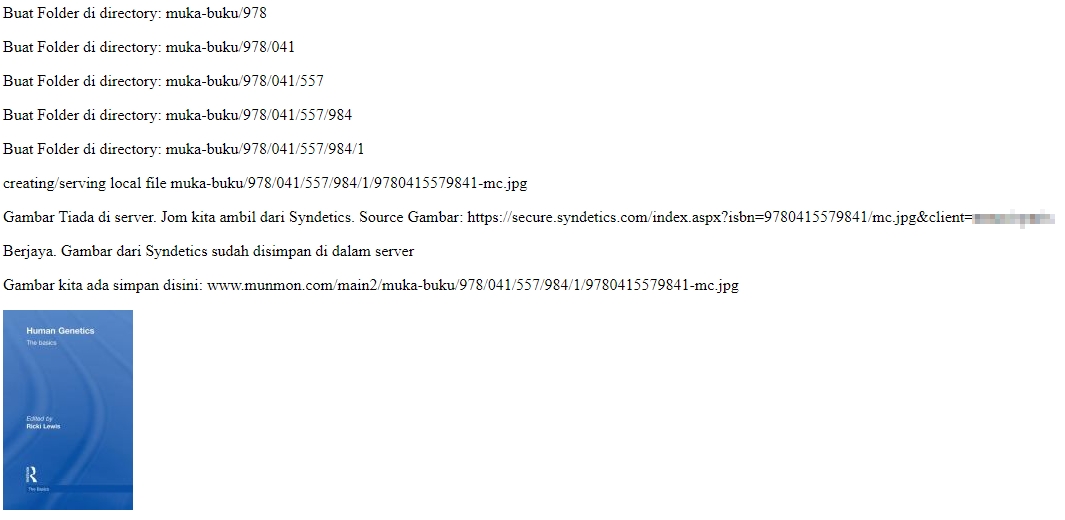
Di bawah adalah Print Out dari script tersebut sekiranya TestingCode = True serta gambar dan folder tersebut tidak wujud di dalam server.
Buat Folder di directory: muka-buku/978
Buat Folder di directory: muka-buku/978/041
Buat Folder di directory: muka-buku/978/041/557
Buat Folder di directory: muka-buku/978/041/557/984
Buat Folder di directory: muka-buku/978/041/557/984/1
creating/serving local file muka-buku/978/041/557/984/1/9780415579841-mc.jpg
Gambar Tiada di server. Jom kita ambil dari Syndetics. Source Gambar: https://secure.syndetics.com/index.aspx?isbn=9780415579841/mc.jpg&client=RAHSIA
Berjaya. Gambar dari Syndetics sudah disimpan di dalam server
Gambar kita ada simpan disini: www.munmon.com/main2/muka-buku/978/041/557/984/1/9780415579841-mc.jpg
Test Run (Gambar dan Folder Ada)
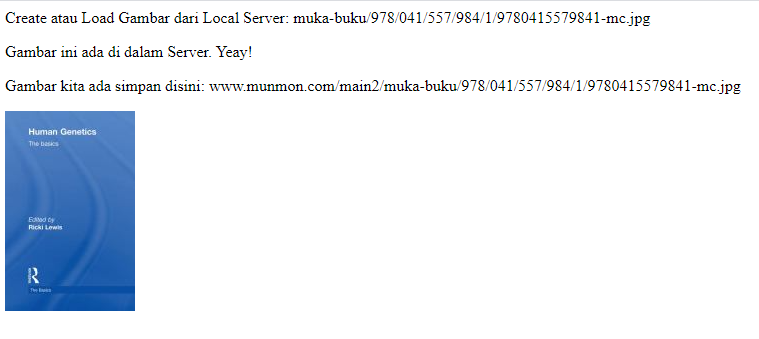
Script yang sama tapi gambar serta folder itu wujud. Berikut adalah Print Out dari script jika kita on kan setting TestingCode.
Create atau Load Gambar dari Local Server: muka-buku/978/041/557/984/1/9780415579841-mc.jpg
Gambar ini ada di dalam Server. Yeay!
Gambar kita ada simpan disini: www.munmon.com/main2/muka-buku/978/041/557/984/1/9780415579841-mc.jpg
Di bawah adalah keseluruhan script sekiranya berminat untuk guna. Saya lesenkan code ini dibawah dilesenkan di bawah CC BY-NC 4.0. Download Script di bawah jika mahu details dan description functionnya.
//Masukkan Nama Folder di sini
define('KEPALA', 'muka-buku');
// Masukkan Nama Lesen Library
define('LESEN', 'RAHSIA-XXXXX-RAHSIA');
// Ini gambar default jika tak ada Gambar (
define('GAMBAR-TIADA', 'muka-buku/transparent.gif');
$TestingCode = False;
if ($TestingCode)
header("Content-type: text/html");
$size = strtolower($_REQUEST['size']);
if ('sc' != $size && 'mc' != $size && 'lc' != $size)
{
print "<p>ERROR - Illegal size. Must be either LC (Small), MC (Medium) or LC (Large). Please refer Syndetics Documentation </p>";
exit;
}
$isbn = strtoupper(preg_replace('/[^0-9Xx]/', '', $_REQUEST['isbn']));
if (10 != strlen($isbn) && 13 != strlen($isbn))
{
print "<p>Error - ISBN must be either 10 or 13 Characters</p>";
exit;
}
$directory = BikinFolder(KEPALA, $isbn, $TestingCode);
$GambarMukaBuku = "${directory}/${isbn}-${size}.jpg";
if ($TestingCode)
print "<p>Create atau Load Gambar dari Local Server: $GambarMukaBuku</p>\n";
if ( ! file_exists($GambarMukaBuku) )
{
$sourceURL = 'https://secure.syndetics.com/index.aspx?isbn=' . "$isbn" . "/mc.jpg&client=" . LESEN;
if ($TestingCode)
print "<p>Gambar Tiada di server. Jom kita ambil dari Syndetics. Source Gambar: $sourceURL</p>\n";
if ($remote = fopen($sourceURL, 'r') )
{
$image = '';
while ( ! feof($remote) )
$image .= fread($remote, 8192);
fclose($remote);
if (strlen($image) >= 100 && $local = fopen($GambarMukaBuku, 'w'))
{
fwrite($local, $image);
fclose($local);
if ($TestingCode)
print "<p>Berjaya. Gambar dari Syndetics sudah disimpan di dalam server</p>\n";
}
}
}
else
{
if ($TestingCode)
print "<p>Gambar ini ada di dalam Server. Yeay!</p>\n";
}
$GambarKitaSimpan = file_exists($GambarMukaBuku) ? $GambarMukaBuku : GAMBAR-TIADA;
if ($TestingCode)
{
print "<p>Gambar kita ada simpan disini: ";
print $_SERVER['SERVER_NAME'] . "/" . basename(getcwd()) ."/" . $GambarKitaSimpan;
print "</p>\n";
;
}
else
{
header("Content-Type: image/jpeg");
header("Content-Length: " . filesize($GambarKitaSimpan));
header("X-Pad: avoid browser bug");
}
print "<img class=thumber3 src='{$GambarKitaSimpan}'>";
function BikinFolder($KEPALA, $isbn, $TestingCode)
{
$parts = Array ($KEPALA,
substr($isbn, 0, 3),
substr($isbn, 3, 3),
substr($isbn, 6, 3),
substr($isbn, 9, 3));
if (13 == strlen($isbn))
array_push($parts, substr($isbn, 12, 3));
$dirName = join('/', $parts);
if (file_exists($dirName))
return $dirName;
$path = $KEPALA;
for ($i = 1; $i < count($parts); $i++)
{
$path .= '/' . $parts[$i];
if ($TestingCode)
print "<p>Buat Folder di directory: $path</p>\n";
@mkdir($path);
}
return $dirName;
}
While sorting out old images, I came across with this picture, the core values of Librarianship. These are the blocks and stones that define us… Librarians.
Generally, there are 11 values that each librarian should believe and uphold. These are our commandments; our values; our honour; our codes… our sacred codes. By these lines, every librarian must believe.
The National Library of Malaysia in collaboration with the Department of Statistics Malaysia (DOSM), Educational Technology Division of the Ministry of Education Malaysia, Librarians Association of Malaysia, the Malaysian Public Library Directors Council (MPAM) and Conference of Academic Libraries and National Library of Malaysia (PERPUN) is conducting an Interim Survey on Malaysians Reading Habit 2014. The objectives of this survey are to identify number of books read by Malaysians based on demographic and the trend of reading habit among Malaysians.